Knowledge
What is a Data Product?
A data product provides access to managed data and has clear ownership.
Data Product vs. Data as a Product
The term product comes from the product thinking approach that has found its way into software development in recent years. Zhamak Dehghani applied the term in the second core principle of data mesh: data as a product. It means that software, or now data, is always designed from the consumer's point of view so they get the best user experience. Just like a physical product, these should be consequently developed for the needs of a consumer. They are explained to the customer in a comprehensible way (intuitively or through an instruction manual), they are optimized to be easily accessible in a way that fits best for the user, and perhaps also be advertised within the organization to show the potential. And consequently, they may also have a price that consumers are willing to pay. Data is now seen as valuable for the company and is no longer just a by-product of software development.
The term data product is derived from the data as a product principle and follows its ideas, but is not to be taken synonymously. Let's try with a definition:
A data product is a logical unit that contains all components to process and store domain data for analytical or data-intensive use cases and makes them available to other teams via output ports.
So, a data product is something technical that is implemented by data product developers. It uses data technologies to store and process large data sets, often millions of entries and more. The size of a data product is designed to cover coherent domain concepts or use cases that are valuable on their own. The maximum size is defined by the scope one team can handle. Data products can be roughly compared to microservices or self-contained systems, but using data technologies and serving analytical needs. Despite the term product, data product consumers are usually other internal teams, not external customers.
Data Product Examples
- The team Product Search offers a data product Search Queries that contains all queries that users entered into the search bar, the number of results, and information about the entry the user clicked on.
- The team Article Management offers a data product Articles with article master data, both the current state and the history.
- The team Checkout offers a data product Orders with all orders since 2020. It has two output ports: one with PII included, one with PII redacted.
- The team Fulfillment has a data product Shelf Warmers with all articles that haven't been sold during the last 3 months.
- The team Management Support uses other data products to create a Realtime Business Dashboard data product for the CEO. It does not share data and has no output ports.
- The team Recommendations uses other data products to train an ML model for recommendations. The ML model is shared as a Tensorflow SavedModel directory on an object store. The Marketing team uses this model to make customer-specific recommendations in the newsletter.
Data Product Internal Components
From an engineering and platform perspective, a data product has several components that form a coherent unit. The following diagram shows typical components of a data product: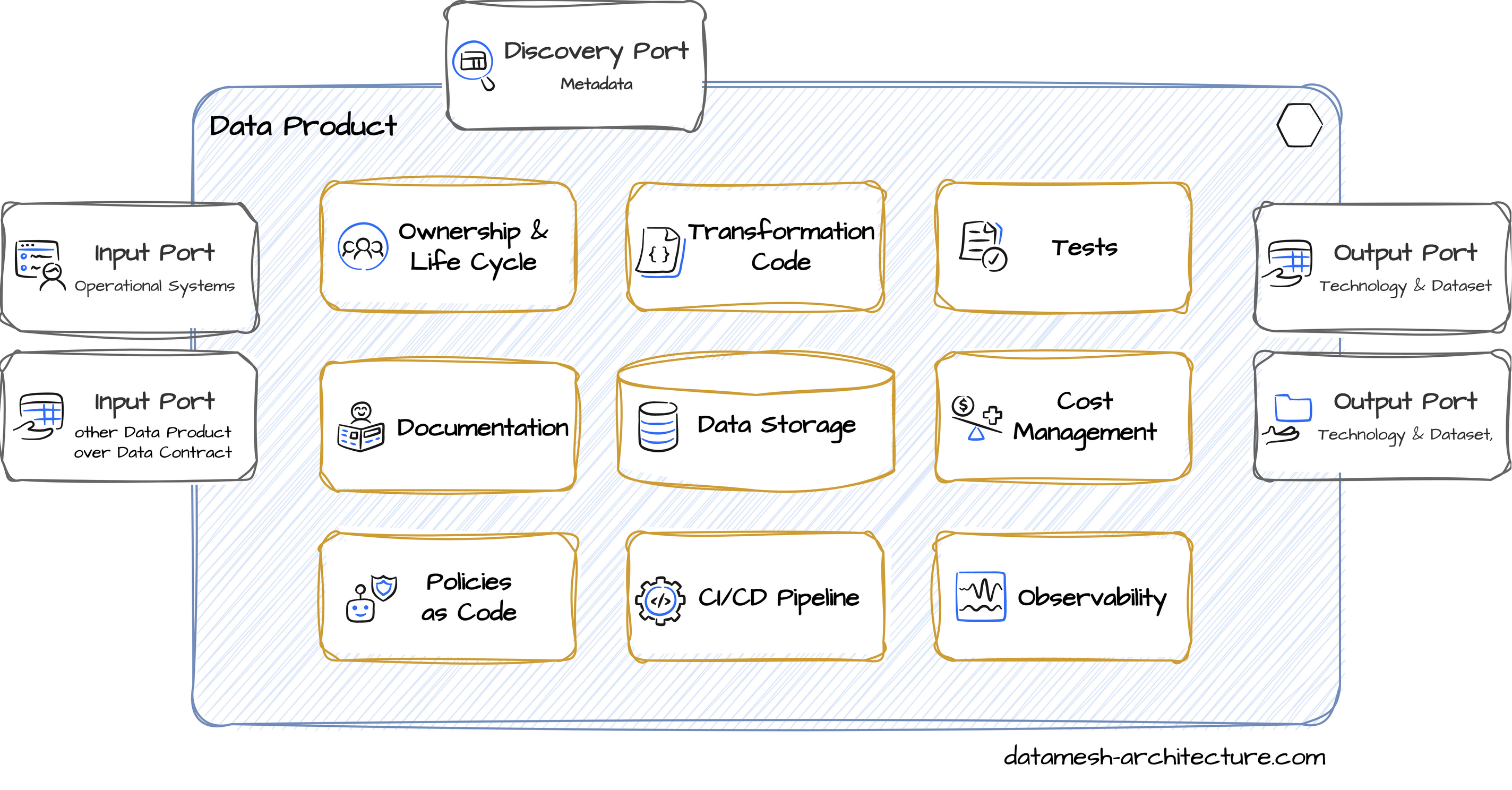 A data product applies the design principle of information hiding. There are interfaces to the outside and internal components.
The actual implementation of the components may vary on the use case and data platform.
A data product applies the design principle of information hiding. There are interfaces to the outside and internal components.
The actual implementation of the components may vary on the use case and data platform.
Output Ports
The output ports represent the main API of a data product: They represent read-only access to structured data sets in the form of tables, files, or topics. A data product can have multiple output ports: They may provide the same data set in different technologies or different datasets in the same technology, e.g., one output port that contains PII data and a second output port with PII redacted. A new output port can also be added, when a structural change is necessary to evolve a data product over time.
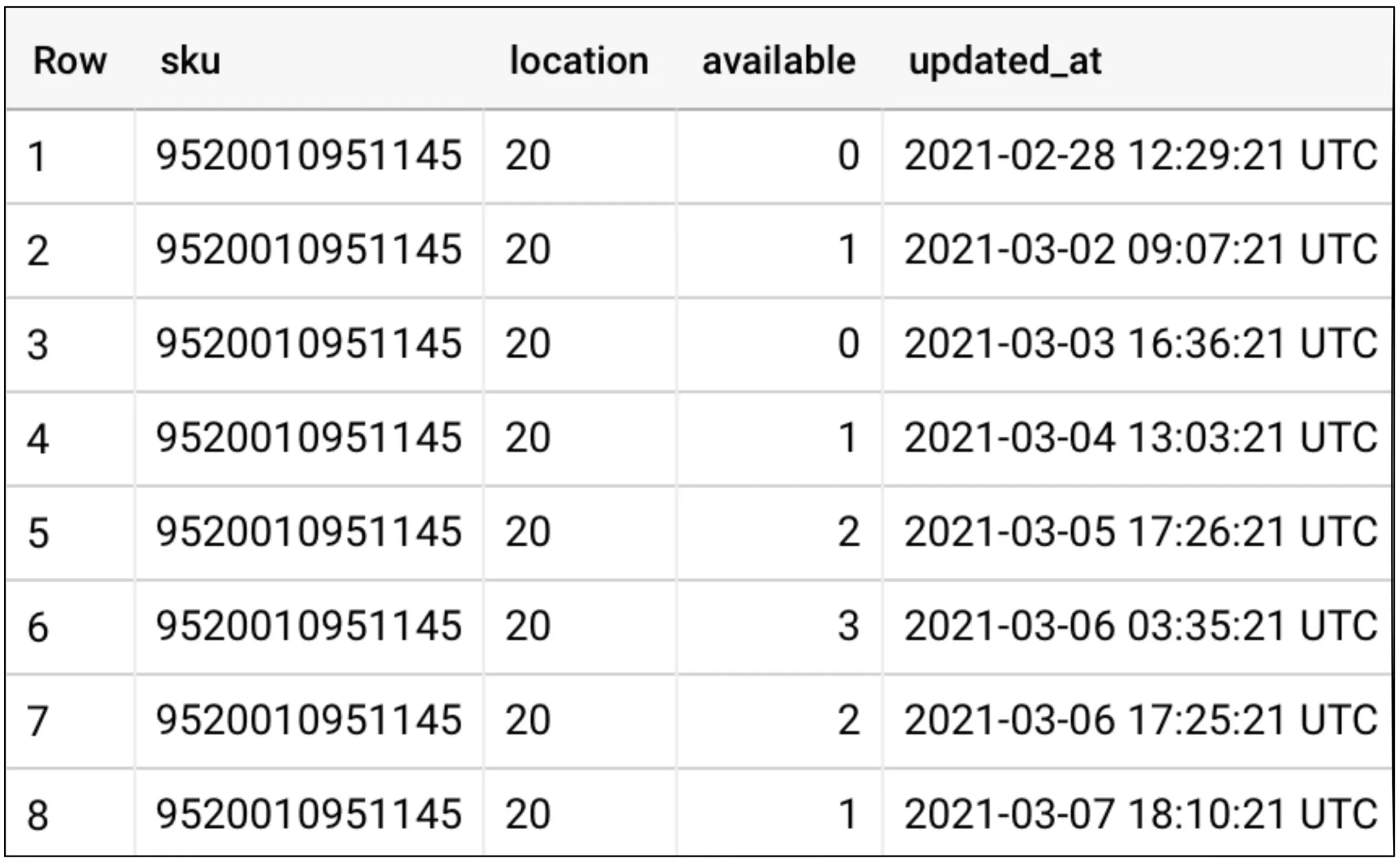
The primary interface technology for an output port is SQL. It allows simple access to large data sets and is supported by practically all analytical tools. An output port is often implemented as a SQL view as an abstraction layer that makes it possible to change the underlying data structure without affecting data consumers. Other interface technologies for output ports are files, or topics for stream processing or as an asynchronous API to operational systems.
Output ports define the model of the provided data set. This model is defined in a schema with all tables, attributes, and types. Typical technologies are SQL DDL, dbt models, Protobuf, Avro, or JSON Schema. The model may also be described in a data catalog entry.
models:
- name: stock_last_updated_v1
description: >
Current state of the stock.
One record per SKU and location with the last updated timestamp.
columns:
- name: sku
type: string
description: Stock Keeping Unit (SKU), the business key of an article.
tests:
- not_null
- name: location
type: string
description: The ID of the warehouse location.
tests:
- not_null
- name: available
type: number
description: The number of articles with this SKU that are available at this location.
tests:
- not_null
- dbt_utils.expression_is_true:
expression: "col_a >= 0"
- name: updated_at
type: timestamptz
description: The business timestamp in UTC when the available was changed.
tests:
- not_nullOutput ports are optional or may be private if a data product only serves team-internal analytical use cases.
Access to output ports is governed through data contracts.
Input Ports
A data product can have two types of data sources: operational systems or other data products.
Teams that develop the operational systems also make their relevant domain data available in data products. Often this is realized via asynchronous topics, preferably by using defined domain events. Ultimately, however, it is up to the domain team to decide how their domain data is ingested into their data products.
Data products may also use other data products over their output port, when they have an agreed data contract. They can be owned by the same team or by other teams. This is typical for consumer-aligned data products or aggregated data products, but also source-aligned data products may link other domain data when useful, e.g., to look up master data.
Discovery Port
Data consumers need to find the data products that are relevant for them. As data usually has a domain-specific meaning, it is important to provide an extensive description of the data model's semantics.
Further metadata, such as contact details, the maturity level, data product usage by others, the data quality tests, and the service-level objectives, is important for data consumers so that they can decide whether a data product is trustworthy and suitable for their use case.
It is good practice to use CI/CD pipeline steps to automatically publish metadata to a data catalog and the data product inventory, such as Entropy Data.
Ownership
A data product is developed and maintained by a single team that understands the business domain, the business processes, and the data. The team is responsible for providing the promised data quality and service-level objectives. A data product has one dedicated contact person, the team's product owner, who is ultimately responsible for the data product and its quality.
The product owner is responsible for the life-cycle and evolution of a data product, incorporating the requirements of the (potential) consumers and domain-internal analytical needs. They also set the price that is charged for the use of a data product.
Transformation Code
Data needs to be cleaned, aggregated, composed, and transformed to implement the output port's schema or to answer analytical questions.
Which technology is used and how code is organized internally are implementation details of a data product. They depend on the data platform and are up to the development teams to decide.
In many cases, SQL queries are used for simple transformations, and Apache Spark for complex pipelines.
A scheduling and orchestration tool, such as Airflow, is used to run the transformation code.
Data Storage
A data product usually needs to store a significant amount of data in some kind of data storage, such as tables or files in an object store. Data storage is provided as a self-service through the data platform. A data product has its own private realm that is isolated from other data products.
Which technology is used and how data is organized internally are implementation details of a data product. They depend on the data platform and are up to the development teams to decide. In many cases, column-oriented storage technologies are used.
Tests
Data products provide managed and high-quality data sets, so, as in any software engineering discipline, tests are essential. There are different types of tests:
Unit tests test the transformation code itself. They use fixed input data and define the expected output data.
Expectation tests run during deployment on the real data models and verify that the source data from the input ports, intermediary models, and the output port meet the defined expectations.
Quality tests run regularly on real data to monitor the service-level objectives.
Documentation
When domain data is shared with other teams, it is important to describe the semantics of the data and the business context of how the data was created.
Besides a description of the data model attributes, good documentation also gives an introduction to what to expect from the data sets and initial hints about which data may be interesting and how to access it.
A good way to implement documentation is to provide an interactive notebook (Jupyter, Google Colab, Databricks Notebook) with example queries.
Cost Management
Data technologies quickly become expensive when used at scale. Therefore, it is important to monitor the costs of data products. They may be the basis for the price that is billed to data consumers, as agreed in data contracts.
Policies as Code
Global policies are the rules of play in the data mesh, defined by the federated governance group — for example, naming conventions, data classification schemes, or access control.
While most policies should be implemented at the data platform level, some need to be configured at the data product level, especially when domain knowledge is required or product owners need to decide on permissions. Examples are column-level classification of domain data, PII tagging, and access control.
CI/CD Pipeline and Scheduling
A data product has its own CI/CD pipeline and infrastructure resource definitions. The CI/CD pipeline is triggered when the transformation code or the data model changes; tests are executed, and the data product is deployed to the data platform in line with global policies. The data platform team may provide modules or templates for the data product teams to use.
A scheduling and orchestration tool, such as Airflow, is used to run the transformation code and tests.
Observability
A data product can have additional ports and capabilities that are not directly used by data consumers but are important for the operation of the data product. These include ports for monitoring, logging, and admin functions.
Open Data Product Standard
By now, there is an industry standard for defining data products — the Bitol Open Data Product Standard (ODPS). It is a YAML-based specification that can be used in combination with its sister, the Open Data Contract Standard (ODCS).
apiVersion: "v1.0.0"
kind: "DataProduct"
id: "shelf-warmers"
name: "Shelf Warmers"
status: "active"
description:
purpose: "A list of articles with no sales in last 6 months"
team:
name: "fulfillment"
tags:
- "demo"
outputPorts:
- name: "snowflake_fulfillment_shelf_warmers"
version: "1"
description: "A list of articles with no sales in last 6 months"
type: "snowflake"
contractId: "snowflake_fulfillment_shelf_warmers"
authoritativeDefinitions:
- type: "Snowflake WebUI"
url: "https://example.com"
customProperties:
- property: "platformRole"
value: "op_shelf_warmers_snowflake_fulfillment_shelf_warmers_role"
- property: "status"
value: "active"
- property: "autoApprove"
value: true
- property: "containsPii"
value: false
- property: "server"
value:
schema: "SHELF_WARMERS"
account: "lmtabcd-xn12345"
database: "FULFILLMENT_DB"
- property: "environment"
value: "prod"
- name: "s3_fulfillment_shelf_warmers"
version: "1"
description: "A list of articles with no sales in last 6 months"
type: "s3"
contractId: "snowflake_fulfillment_shelf_warmers"
authoritativeDefinitions:
- type: "AWS Console"
url: "https://example.com"
customProperties:
- property: "platformRole"
value: "op_shelf_warmers_s3_fulfillment_shelf_warmers_role"
- property: "status"
value: "active"
- property: "autoApprove"
value: true
- property: "containsPii"
value: false
- property: "server"
value:
location: "s3://my-bucket"
- property: "environment"
value: "prod"
customProperties:
- property: "platformRole"
value: "dp_shelf_warmers_role"
- property: "type"
value: "consumer-aligned"
A formal data product specification can act as a foundation for automation and to provide metadata to other systems, such as a data catalog or a data product marketplace.
Data Product Implementation
Now let's look at an example of how an actual data product can be implemented. Depending on the data platform, there are different ways to implement a data product:
- Databricks: a data product should be implemented as a Databricks Asset Bundle
- Snowflake: a data product is typically a dbt project
- BigQuery: a data product is typically a dbt project
- AWS S3 and Athena: a data product is often managed as a Terraform project
- Kafka: a Java project
In this example, we use an AWS S3 and Athena tech stack. The data platform team provides a Terraform module that provisions all necessary services on the data platform to run a data product, in line with the policies and conventions defined by the governance group.
The data product developers have one Git repository per data product. They use the provided Terraform module and configure it for their data product. In the same repository, they define the transformation code as a SQL query and a JSON schema file with the model of the output port and a detailed description of the data model.
# dataproduct.tf
module shelf_warmers {
source = "git@github.com:datamesh-architecture/terraform-dataproduct-aws-athena.git"
version = "0.2.1"
domain = "fulfillment"
name = "shelf_warmers"
description = "Shelf warmers are products that are not selling for 3 months and are taking up space on the shelf."
schedule = "0 0 * * ? *" # Run at 00:00 am (UTC) every day
transform = {
query = "sql/transform.sql"
}
output = {
format = "PARQUET"
schema = "schema/shelf_warmers.schema.json"
roles_allowed = ["coo"] # Policy as code
}
}
With terraform apply, usually triggered through the CI/CD-pipeline, all required resources are provisioned, such as S3 buckets, AWS Athena resources, and lambda functions.
Also, permissions are created in AWS IAM.
The pipeline also pushes metadata to the data catalog and data product inventory.
Find an example of a Terraform module implementation on GitHub.
Entropy Data
Entropy Data is a software to manage data products and data contracts and turn them into an easy-to-use data marketplace. It uses the ODPS standard to build a comprehensive data product inventory. Data products can be imported from data platforms and data catalogs, and metadata can be enhanced easily via a Web UI, YAML editor, APIs, and even Excel editors. Data consumers can browse the data product inventory, find the data products that are relevant to them, and request access.
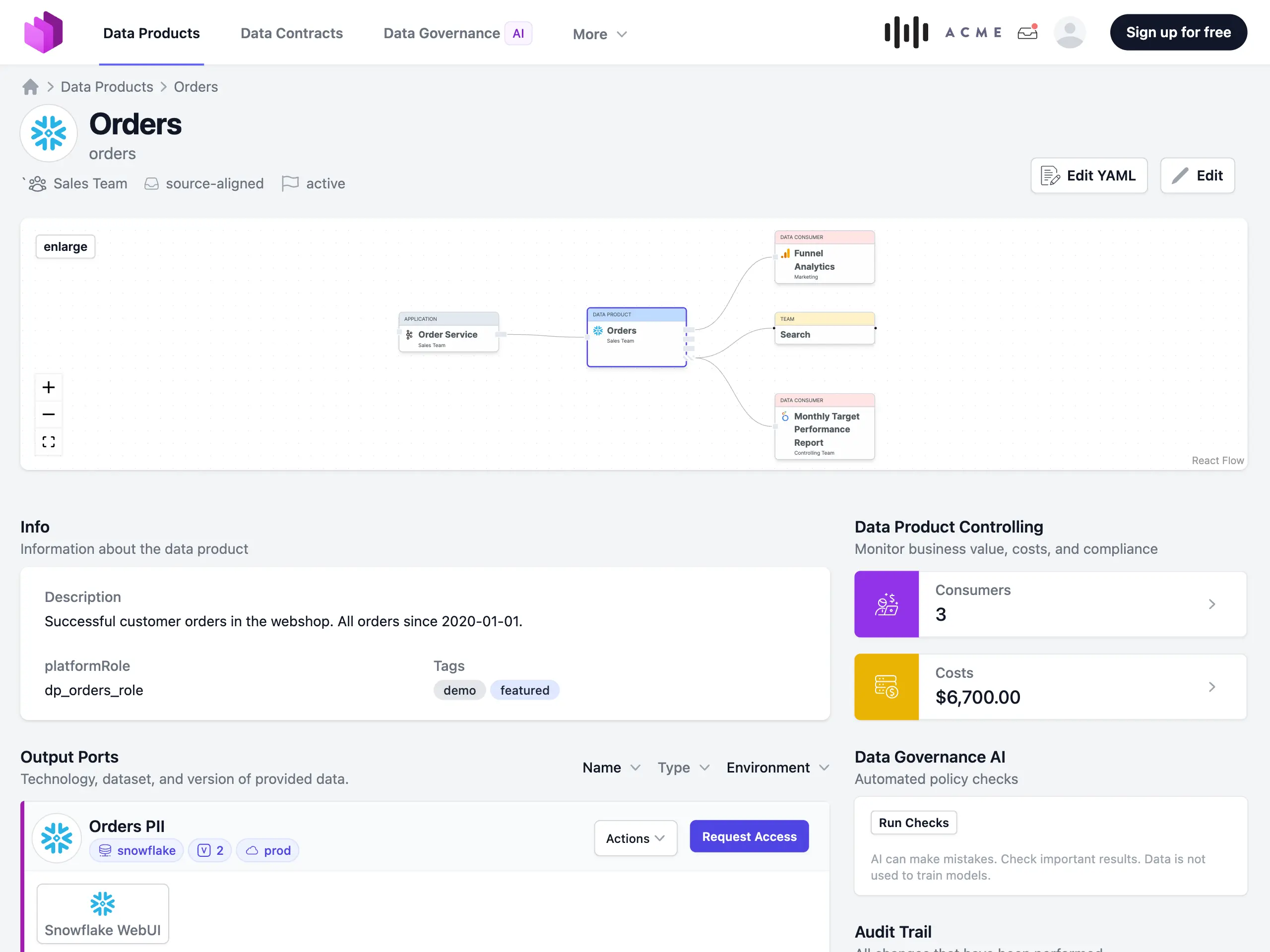
Through the REST API, Entropy Data integrates with all data platforms and triggers the automated creation of IAM permissions in the data platform once a data contract is created or updated.
Sign up now for free, or explore the clickable demo of Entropy Data.