Knowledge
What is a Data Contract?
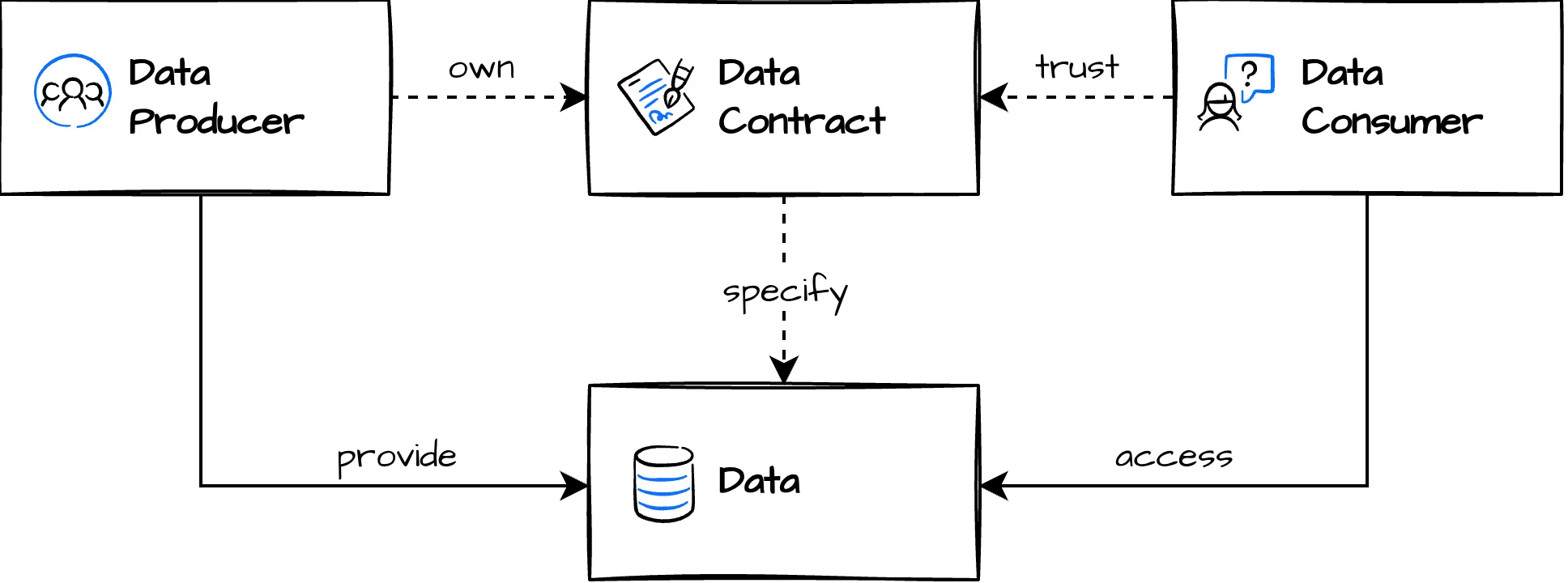
A data contract is a document that defines the ownership, structure, semantics, quality, and terms of use for exchanging data between a data producer and their consumers. Think of an API, but for data.
Why Data Contracts?
Organizations struggle with good metadata and fragile data pipelines that break from upstream changes, poor communication between data producers and consumers, and data engineers overwhelmed by competing demands. Data contracts solve these problems by establishing explicit expectations on data across these dimensions:
- Ownership – Responsibility for providing correct data
- Schema – Column names, data types, structure
- Semantics – Descriptions and business meaning
- Quality – Validation rules, freshness, completeness
- Terms of Use – Usage rights, SLAs, access policies
Data contracts are a communication tool to express a common understanding of how data should be structured and interpreted. They can be created collaboratively with the data provider and consumer, even before the data product is implemented, a contract-first approach. In development and production, they serve as the basis for code generation, testing, schema validations, quality checks, monitoring, and computational governance to ensure that data products match the agreed-upon expectations.
Open Data Contract Standard (ODCS)
The Open Data Contract Standard (ODCS) is the open standard for defining data contracts in a machine-readable YAML format. Originally developed as the Data Contract Template at PayPal, it is now governed by Bitol, a Linux Foundation AI & Data project.
Here's a simplified example of an ODCS data contract:
apiVersion: v3.1.0
kind: DataContract
id: orders
name: Orders
version: 1.0.0
status: active
description:
purpose: "Provides order and line item data for analytics and reporting"
usage: "Used by analytics team for sales analysis and business intelligence"
limitations: "Contains only the last 2 years of data"
customProperties:
- property: "sensitivity"
value: "secret"
description: "Data contains personally identifiable information"
authoritativeDefinitions:
- url: "https://entropy-data.com/policies/gdpr-compliance"
type: "businessDefinition"
description: "GDPR compliance policy for handling customer data"
schema:
- name: orders
physicalType: TABLE
description: All historic web shop orders since 2020-01-01. Includes successful and cancelled orders.
properties:
- name: order_id
logicalType: string
description: The internal order id for every orders. Do not show this to a customer.
businessName: Internal Order ID
physicalType: UUID
examples:
- 99e8bb10-3785-4634-9664-8dc79eb69d43
primaryKey: true
classification: internal
required: true
unique: true
- name: customer_id
logicalType: string
description: A reference to the customer number
businessName: Customer Number
physicalType: TEXT
examples:
- c123456789
required: true
unique: false
logicalTypeOptions:
minLength: 10
maxLength: 10
authoritativeDefinitions:
- type: definition
url: https://example.com/definitions/sales/customer/customer_id
tags:
- pii:true
classification: internal
criticalDataElement: true
- name: order_total
logicalType: integer
description: The order total amount in cents, including tax, after discounts.
Includes shipping costs.
physicalType: INTEGER
examples:
- "9999"
quality:
- type: text
description: The order_total equals the sum of all related line items.
required: true
businessName: Order Amount
- name: order_timestamp
logicalType: timestamp
description: The time including timezone when the order payment was successfully
confirmed.
physicalType: TIMESTAMPTZ
businessName: Order Date
examples:
- "2025-03-01 14:30:00+01"
- name: order_status
businessName: Status
description: The business status of the order
logicalType: string
physicalType: TEXT
examples:
- shipped
quality:
- type: library
description: Ensure that there are no other status values.
metric: invalidValues
arguments:
validValues:
- pending
- paid
- processing
- shipped
- delivered
- cancelled
- refunded
mustBe: 0
quality:
- type: library
metric: rowCount
mustBeGreaterThan: 100000
description: If there are less than 100k rows, something is wrong.
- name: line_items
physicalType: table
description: Details for each item in an order
properties:
- name: line_item_id
logicalType: string
description: Unique identifier for the line item
physicalType: UUID
examples:
- 12c9ba21-0c44-4e29-ba72-b8fd01c1be30
logicalTypeOptions:
format: uuid
required: true
primaryKey: true
- name: sku
logicalType: string
businessName: Stock Keeping Unit
description: Identifier for the purchased product
physicalType: TEXT
examples:
- 111222333
required: true
- name: price
logicalType: integer
description: Price in cents for this line item including tax
physicalType: INTEGER
examples:
- 9999
required: true
- name: order_id
required: false
primaryKey: false
logicalType: string
physicalType: UUID
relationships:
- type: foreignKey
to: orders.order_id
servers:
- server: production
environment: prod
type: postgres
host: aws-1-eu-central-2.pooler.supabase.com
port: 6543
database: postgres
schema: dp_orders_v1
team:
name: sales
description: This data product is owned by the "Sales" team
members:
- username: john@example.com
name: John Doe
role: Owner
authoritativeDefinitions:
- type: slack
url: https://slack.example.com/teams/sales
roles:
- role: analyst_us
description: Read access for analytics to US orders
- role: analyst_eu
description: Read access for analytics to EU orders
slaProperties:
- property: availability
value: 99.9%
description: Data platform uptime guarantee
- property: retention
value: "1"
unit: year
description: Data will be deleted after 1 year
- property: freshness
value: "24"
unit: hours
# element: orders.order_timestamp # enable this to check freshness with Data Contract CLI
description: Within 24 hours of order placement
- property: support
value: business hours
description: Support only during business hours
price:
priceAmount: 0
priceCurrency: USD
priceUnit: monthly
tags:
- e-commerce
- transactions
- pii
customProperties:
- property: dataPlatformRole
value: role_orders_v1
contractCreatedTs: "2025-01-15T10:00:00Z"
Learn more about the full specification, examples, and tooling at datacontract.com.
Tooling
The Data Contract CLI is an open-source command-line tool for working with data contracts. It can lint and validate contracts, connect to data sources to execute schema and quality tests, detect breaking changes in CI/CD pipelines, and export to various formats.
The Data Contract Editor by Entropy Data is a browser-based editor for authoring data contracts with live preview and validation.
Manage Data Contracts with Entropy Data
Entropy Data provides a web-based platform to manage data products, data contracts, and data usage agreements as a self-service. An event-based API enables seamless integration with any data platform, and every change is recorded in an audit trail.
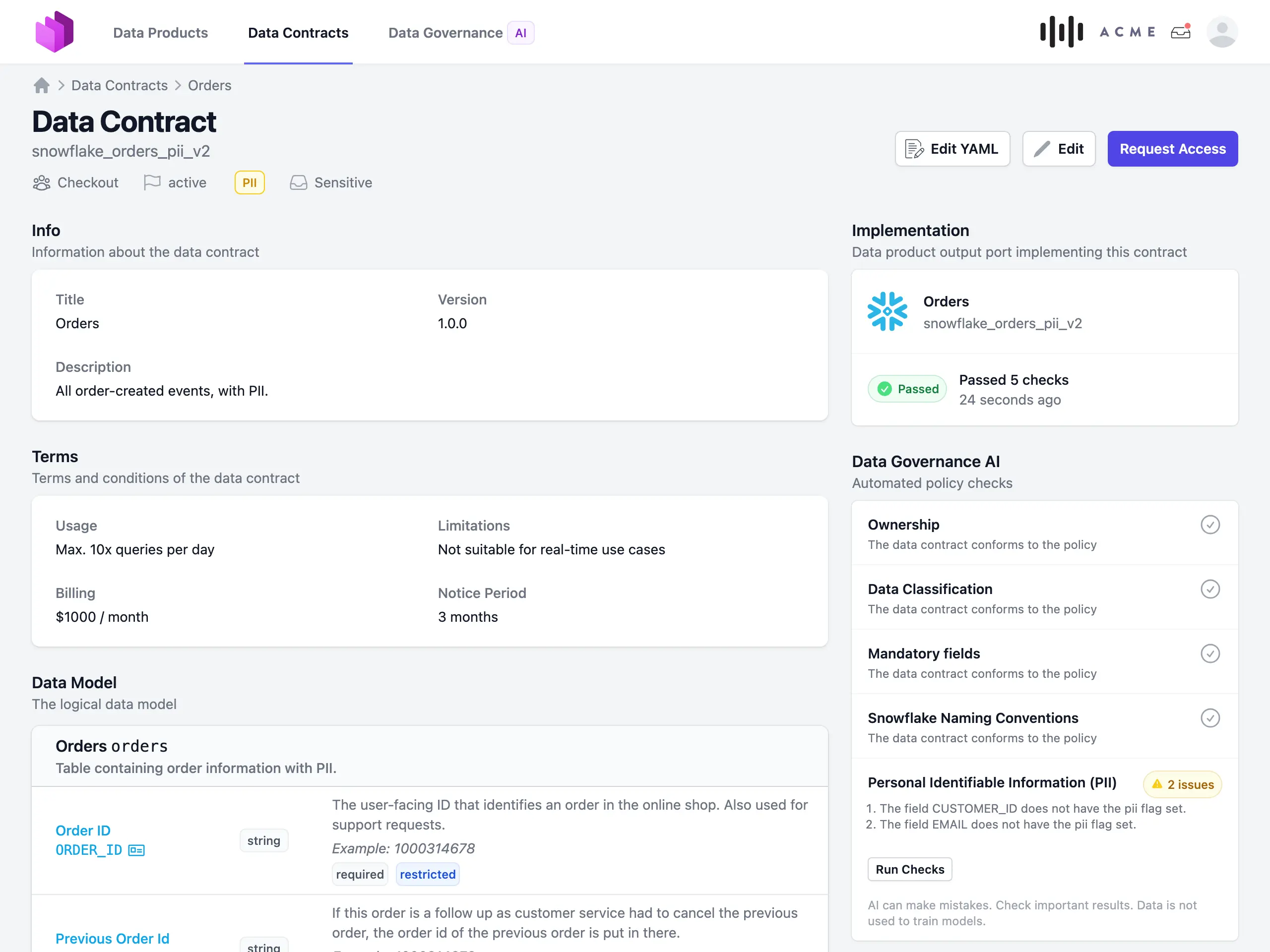
Features include a data product catalog, request and approval workflows for data usage agreements, automated permission management, and visualization of your data mesh as an interactive map.
Start for Free, or explore the interactive demo.